上一篇,我們完成了一個神經元的計算,如果要完成整個神經網路的計算,一個一個神經元撰寫,程式碼可能要很多迴圈,才能完成多層式的神經網路,因此,深度學習套件又導入【神經層】(Layer)的函數,直接作一層層的串連,就方便許多了。
這次我們就利用神經層串連一個神經網路,辨識手寫阿拉伯數字,終極目標我們要撰寫一個視窗介面親自實驗模型的準確性。
2017年我使用 Keras 獨立套件撰寫辨識手寫阿拉伯數字的程式,請參閱【Day 02:撰寫第一支 Neural Network 程式 -- 阿拉伯數字辨識】,現在,我們改用TensorFlow Keras 寫類似的程式,讀者可比較其差異,其實,大部份的程式是相同的,只是命名空間不同罷了。
Tensorflow 1.x 版使用會話(Session)及運算圖(Computational Grahp)的概念,撰寫一支簡單的程式就要花費好大的功夫,被 Facebook PyTorch 批評的體無完膚,包括:
因此,Tensorflow 2.x 大改版,作了以下的改變:
並且在官網直接放上一支超短程式,示範如何辨識手寫阿拉伯數字,要證明Tensorflow超好用,現在我們就來看看這支程式,以下我逐行加了一些註解。
import tensorflow as tf
mnist = tf.keras.datasets.mnist
# 匯入 MNIST 手寫阿拉伯數字 訓練資料
(x_train, y_train),(x_test, y_test) = mnist.load_data()
# 特徵縮放,使用常態化(Normalization),公式 = (x - min) / (max - min)
# 顏色範圍:0~255,所以,公式簡化為 x / 255
x_train, x_test = x_train / 255.0, x_test / 255.0
# 建立模型
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
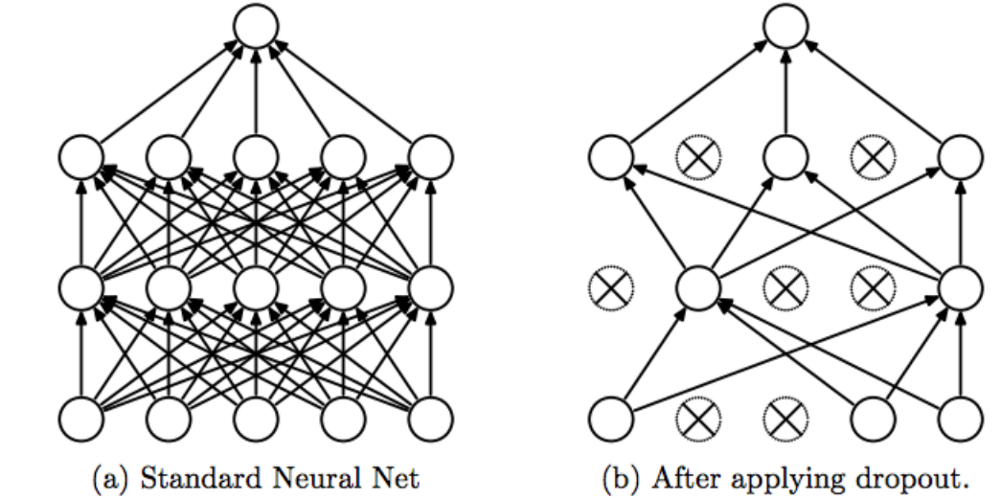
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
# 設定優化器(optimizer)、損失函數(loss)、效能衡量指標(metrics)的類別
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 模型訓練
model.fit(x_train, y_train, epochs=5)
# 模型評估,打分數
model.evaluate(x_test, y_test)
模型結構如下: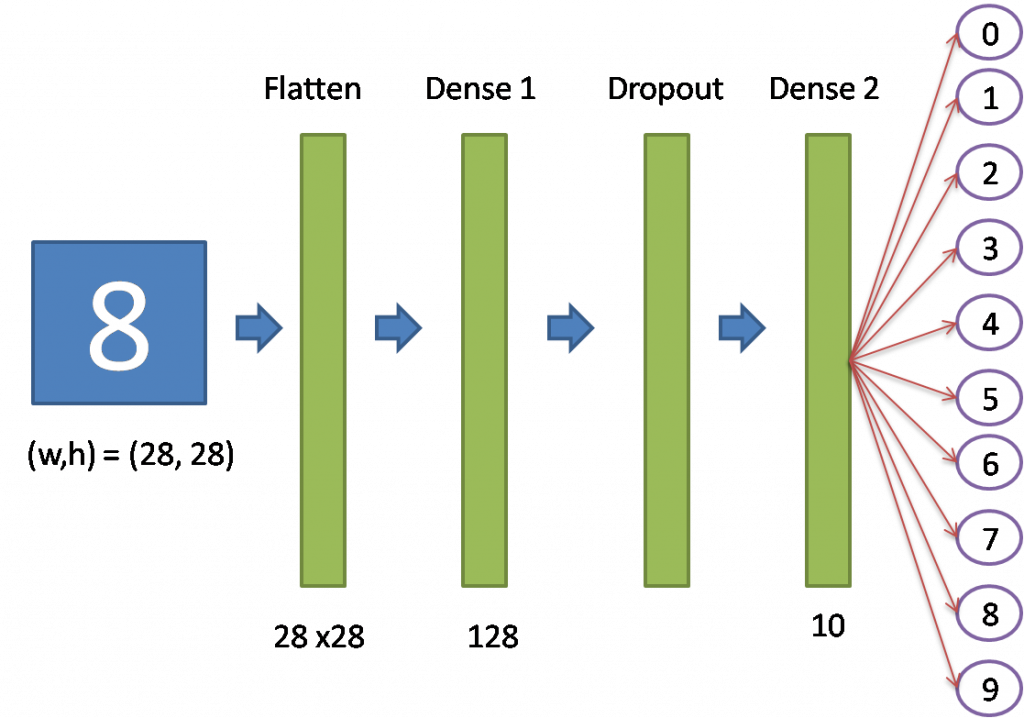
各神經層處理程序如下(tf.keras.models.Sequential那一段):
上述的程式扣除註解,不到10行,辨識的準確率高達97~98%,真是厲害 !!
要徹底了解上述程式,建議在不清楚的指令行後面,加一些除錯訊息,例如 03_01_MNIST.ipynb。
# 將非0的數字轉為1,顯示第1張圖片
data = x_train[0].copy()
data[data>0]=1
# 將轉換後二維內容顯示出來,隱約可以看出數字為 5
text_image=[]
for i in range(data.shape[0]):
text_image.append(''.join(str(data[i])))
text_image

圖一. 將非0的數字轉為1,隱約可以看出數字為 5
# 訓練
history = model.fit(x_train_norm, y_train, epochs=5, validation_split=0.2)
# 對訓練過程的準確度繪圖
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'], 'r')
plt.plot(history.history['val_accuracy'], 'g')
# 對訓練過程的損失函數繪圖
plt.plot(history.history['loss'], 'r')
plt.plot(history.history['val_loss'], 'g')
# 實際預測 20 筆
predictions = model.predict_classes(x_test_norm)
# get prediction result
print('prediction:', predictions[0:20])
print('actual :', y_test[0:20])
# 顯示錯誤的資料圖像
X2 = x_test[8,:,:]
plt.imshow(X2.reshape(28,28))
plt.show()

圖二. 實際為5,辨識為6的圖像
# 使用小畫家,寫0~9,實際測試看看
from skimage import io
from skimage.transform import resize
import numpy as np
uploaded_file = './myDigits/8.png'
image1 = io.imread(uploaded_file, as_gray=True)
#image1 = Image.open(uploaded_file).convert('LA')
image_resized = resize(image1, (28, 28), anti_aliasing=True)
X1 = image_resized.reshape(1,28, 28) #/ 255
# 反轉顏色
# 顏色0為白色,與RGB顏色不同,(0,0,0) 為黑色。
X1 = np.abs(1-X1)
predictions = model.predict_classes(X1)
print(predictions)
# 顯示模型的彙總資訊
model.summary()
# 模型存檔
model.save('model.h5')
# 模型載入
model = tf.keras.models.load_model('model.h5')
# 繪製模型
# 需安裝 graphviz (https://www.graphviz.org/download/)
# 將安裝路徑 C:\Program Files (x86)\Graphviz2.38\bin 新增至環境變數 path 中
# pip install graphviz
# pip install pydotplus
tf.keras.utils.plot_model(model, to_file='model.png')
檔案名稱為 03_01_MNIST.ipynb。
讀到這裡,讀者對神經網路應該有些心得,但是,應該也會有更多的疑問。
我的心得如下:
讀完上文,初次接觸深度學習的讀者應該還是會有許多疑問:
後續我們就來一一探討這些問題,下一篇我們先來說明如何作效能調校(Performance Tuning)。
本篇範例包括 03_01_MNIST.ipynb,可自【這裡】下載。
您好,metrics的部分我若不使用accuracy而是precision就無法執行了,請問這是為什麼呢?
使用其他metrics,須將y轉為 one-hot encoding。
y_train = tf.keras.utils.to_categorical(y_train)
y_test = tf.keras.utils.to_categorical(y_test)
# 設定優化器(optimizer)、損失函數(loss)、效能衡量指標(metrics)的類別
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['Precision'])
可以跑了,感謝您

